This blog is the summary of the talk given by Dr. Fergus Imrie (University of California, Los Angeles - UCLA), on self-supervised learning of ‘omics’, at the Pathcheck/DICE Global Health Innovators Seminar.
Firstly, Dr, Fergus sheds light on the history of human genome sequencing and how the cost has reduced drastically, due to the developing technology, leading to an exponential rise in genetic testing.
“OMICS” is one of the key research areas of our times which will have far-reaching consequences for the health and well-being of humankind. This generally refers to the study, pattern analysis, markers, and measurements of a large family of cellular molecules such as genes, proteins, etc., and has been named by adding the suffix “omics”. Typically, some of the omics that are extensively researched include:
- Genomics – Study of Genes
- Proteomics – Study of Proteins
- Transcriptomics – Study of mRNA
- Glycomics – Study of cellular Carbohydrates
Since genome testing and sequencing have risen across the world due to various Government and private projects, there is a lot of data available from various agencies. As the data available is huge, it is becoming an impossible task to manually study and analyze all the information and patterns. This is where AI and self-supervised machine learning in particular step in. They have a huge potential for data analysis which can finally lead to giving us great insights into human biology with specific emphasis on health, effects of medication, and thereby overall well-being.
Primarily there are 2 types of data available, 'labeled data' and 'unlabeled data'. In general, labeled data is available in lesser quantities, and is more expensive to obtain while a large quantity of unlabeled data is more easily available. Machine learning is the process in which the machine improves its analysis and results with more data being provided, in other words, the more data the better (at least in many cases). Here the approach of Dr. Fergus is to use both labeled and unlabeled data to get the best possible results. The idea is to let the machine do the learning with unlabeled data to start off and then draw its own analysis and conclusions. Once this is done, a limited amount of labeled data is introduced which will help the machine to fine-tune its previous learnings. This data analysis is done through processes that were developed by Dr. Fergus and his team and are called VIME and SEFS. The results from this approach have had very high accuracy values as compared to other existing approaches. Some graphs illustrating the effectiveness of this approach are appended below.
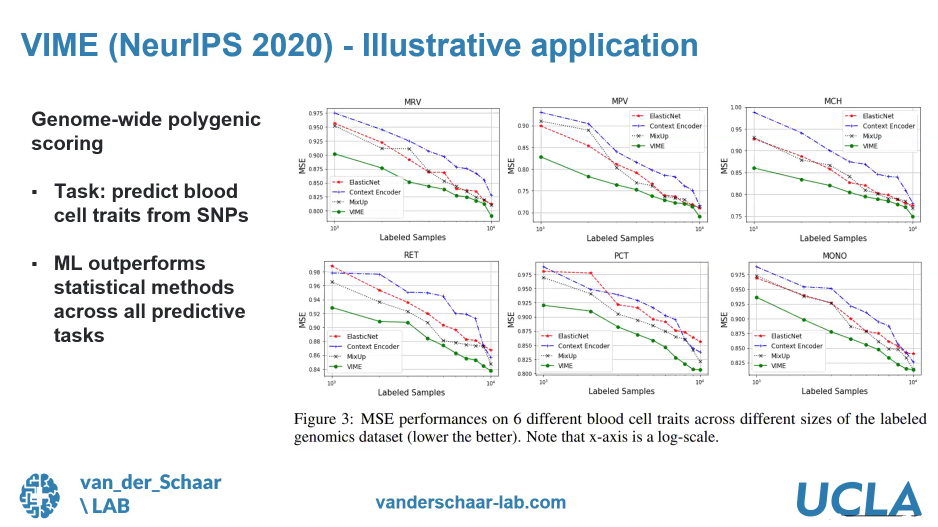
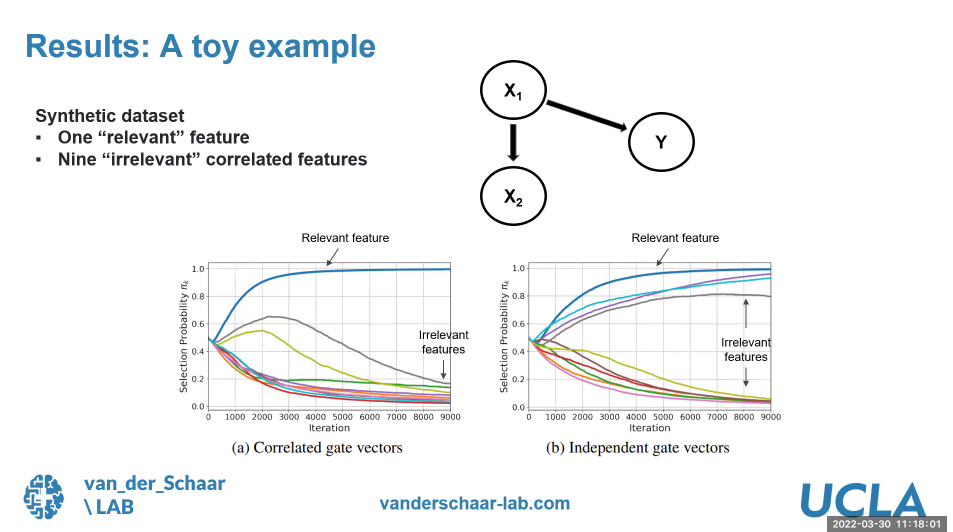
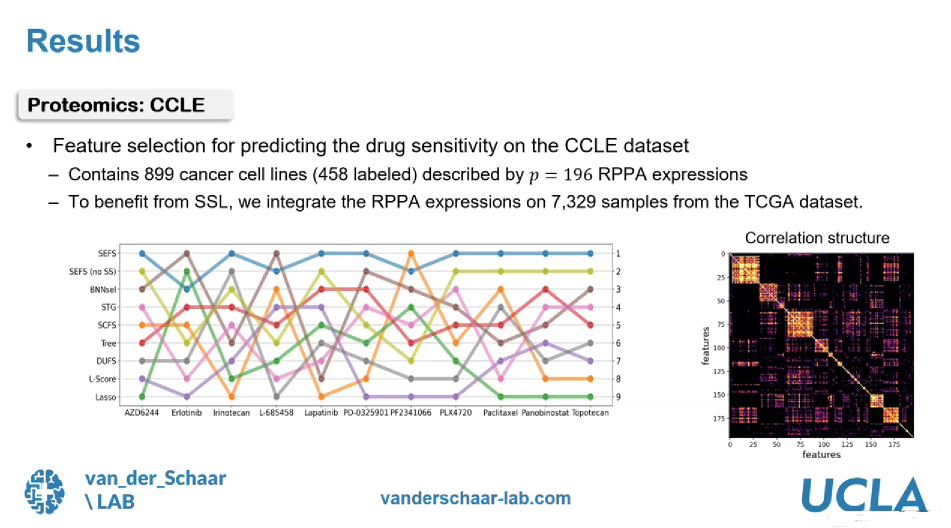
VIME was presented at the NeurIPS conference 2020 and can be found in the below link
https://vanderschaar-lab.com/papers/NeurIPS2020_VIME.pdf
SEFS will be presented in ICLR 2022 and can be found at link
Some of the applications of self-supervised learning on omics are seen below
- Polygenic risk scores - To predict the risk of an individual developing a disease/health problem based on their genomics. The reasons/patterns that lead to this can also be identified. This can lead to designing the right solutions.
- Proteomics – This predicts the effect of different drugs on target molecules in our body which ultimately leads to the development of effective medication. Further, the existing medications can also be assessed for their effectiveness.
- Transcriptomics – Distinguishing sub-population of T cells and other matters related to mRNA
As health care and well-being is a top global priority, OMICS and the Self Supervised ML approach will get bigger and better going forward.
.
Q & A session:
In the Session, there were a few interesting exchanges on the subject. Some of the questions and responses are:
Q: Can VIME and SEFS be used for feature selection related to images as this can have significant value in the study of cancer and other diseases.
A: Dr. Fergus conveyed that both VIME and SEFS have been designed for feature selection on tabular data as they provide more value at the moment for the type of data available. Also, both VIME and SEFS are not designed for image feature selection.
Q: Will both VIME and SEFS be available as open-source which could be used by others for research? Is Dr. Fergus’s Lab ready to collaborate with interesting people/agencies for research works?
A: Dr. Fergus confirmed that VIME is already open source and can be used by those interested. SEFS will be presented at a conference a little later after which it will be made open source. He informed that his Lab is interested to collaborate with anyone interested in research on these subjects and they would like to maximize the benefits coming out of their VIME and SEFS.